为 KeyDB 实现子键过期功能
一个被长期请求但 Redis 未实现的功能 是为包含子成员的数据类型(如 SET 和 HASH)的单个成员设置过期的能力。Redis 不添加此功能的理由对 Redis 来说是合理的,但 KeyDB 专注于提供一款易于使用的高性能产品,而试图在没有内置命令的情况下实现此功能非常困难,因此添加此功能就显得顺理成章了。
KeyDB 最初尝试添加子键过期功能时采用了一种直接的方法,即为每个过期项添加一个用于潜在子键过期的向量,但这导致了某些性能问题。在这篇博客文章中,我们探讨了这些问题的根本原因,以及我们如何使用更复杂的数据结构(如哈希表)来解决这些问题。
EXPIREMEMBER 命令#
KeyDB 通过一个新命令 EXPIREMEMBER 来实现子键过期。该命令接收一个键、一个子键和一个过期时间,并在指定时间仅从映射到该键的数据结构中移除该子键,而保留值的其余部分不变。
以下是一个使用 HASH 的例子
在上面的例子中,我们将成员 f3 设置为在 10 秒后过期。10 秒后,它消失了,而其他成员仍然存在。
KeyDB 如何实现 EXPIREMEMBER#
KeyDB 通过两种不同的方式使键和子键过期:被动过期和主动过期。被动过期发生在每次访问键或子键时,它会简单地检查该键或子键是否已过期并将其移除。主动过期则是由 KeyDB 在执行期间定期运行的一种算法引起的,KeyDB 会遍历待过期的项,如果任何项到期,则移除相应的键或子键。
在实现 EXPIREMEMBER 时,一个重要的考虑因素是如何存储键和子键的过期数据。存储方式应能让主动过期算法快速遍历最可能已经过期的键和子键,同时也要让被动过期能够快速找到相关的键和子键,并且对 KeyDB 内存使用的影响最小化。KeyDB 使用了一个按过期时间排序的向量,但这导致被动过期查找期间的查找时间呈线性增加,从而对包含待处理子键过期项的值的其他操作产生巨大影响。为了解决这个问题,我们考虑使用哈希表,它提供常量时间的查找。
排序向量的优点
- 使用排序向量,主动过期算法可以轻松地遍历待过期的项,并使所有到期的键和子键过期,这使得 KeyDB 能够确保不常访问的过期键被迅速移除。
- 向量是一种内存高效的数据结构,它使用存储过期项所需的最少内存。
排序向量的缺点
- 添加新的过期项和修改现有的过期项需要 O(log(n)) 的搜索,以确保它被放置在正确的位置,这可能导致随着待过期项数量的增长,过期命令变慢。
- 被动过期需要查找特定键的过期信息,在按过期时间排序的向量中,这需要 O(n) 的搜索,这导致所有访问具有大量待处理子键过期项的键的命令都出现大规模的性能下降。
哈希表的优点
- 添加新的过期项和修改现有的过期项可以在 O(1) 的期望时间内快速完成。
- 被动过期需要查找特定键的过期信息,在哈希表中,这可以在 O(1) 的期望时间内快速完成。
哈希表的缺点
- 哈希表使得主动过期算法更难遍历待过期的项,增加了移除不常访问的过期键的时间。
- 哈希表在内存效率方面不是很高,通常在负载因子约为 2/3 时达到最佳性能,这意味着存储等量数据比向量多用 50% 的内存。
这是一张图表,比较了两种实现方式下,对一个拥有 1000000 个条目和 n 个待处理子键过期项的 HASH 对象的操作数/秒
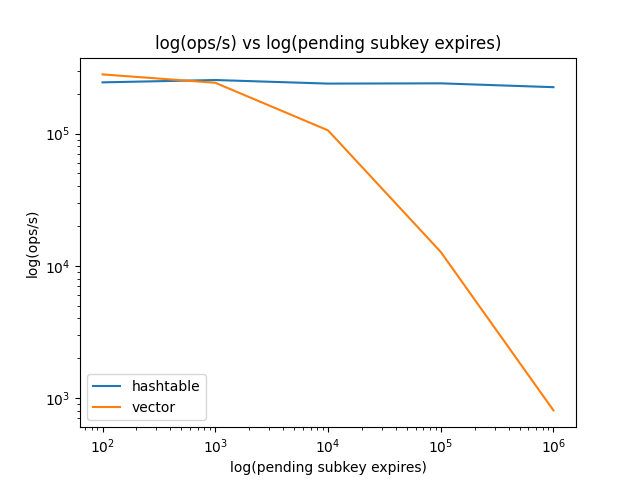
根据这些结果,切换到哈希表似乎是正确的选择!
为 EXPIREMEMBER 定制哈希表#
切换到哈希表的主要缺点是对主动过期算法遍历待过期项的能力的影响,这使得它难以首先找到已到期的项。我们做了一些修改,包括:
- 按过期时间对哈希表内的各个桶进行排序,每个桶都有一个固定的最大条目数量,因此保持它们的排序成本为 O(1)。
- 创建一个智能迭代器,它按顺序访问桶。结合第一点,这可以最小化我们在遍历表时查看未到期项的数量。
切换到哈希表为被动过期带来了明显的性能提升,并且通过使用一个改进的哈希表来最小化对主动过期算法的影响,这个哈希表提高了快速找到过期子键的概率,我们最终得到一个升级的实现,它增强了 KeyDB 提供 EXPIREMEMBER 命令的能力,而不会影响整体性能。
试用 KeyDB#
如果您喜欢这些功能,想要试用,或者想了解更多信息,您可以在这里找到这个开源项目,或者您可以查看我们的Docker 镜像。
关注 KeyDB 的最新动态#
我们正在开发一些非常酷的功能。要了解我们的最新动态,请关注我们的以下渠道之一