Redis SCAN 对性能的影响以及 KeyDB 如何改进它
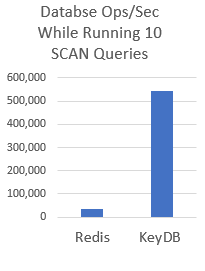
SCAN 是一个强大的数据查询工具,但其阻塞性质在大量使用时会严重影响性能。KeyDB 改变了此命令的性质,实现了数量级的性能提升!
本文探讨了使用 SCAN 命令的局限性及其对性能的影响。文章展示了 Redis 会出现的严重性能下降,并介绍了 KeyDB 如何通过实现 MVCC 架构来解决这个问题,使 SCAN 变为非阻塞操作,从而避免对性能产生任何负面影响。
KEYS vs SCAN#
SCAN 函数的创建是为了解决阻塞的 KEYS 命令,该命令在生产环境中使用时可能会引发重大问题。许多 Redis 用户都非常清楚这种减速对其生产工作负载造成的后果。
KEYS 命令和 SCAN 命令都可以搜索所有匹配特定模式的键。两者的区别在于,SCAN 使用游标分批迭代键空间,以防止在查询期间完全阻塞数据库。
基本用法如下
下面的例子搜索所有键名中包含模式“22”的键。游标从位置 0 开始,一次搜索 100 个键。返回的结果将首先返回下一个游标号,然后是该批次中键名包含“22”的所有值。
有关使用 SCAN 的更多信息,请参阅此处的文档 https://docs.keydb.cn/docs/commands/#scan
SCAN COUNT#
COUNT 是每次游标迭代时要搜索的键的数量。因此,COUNT 值越小,对于给定的数据集所需的增量迭代次数就越多。下面的图表显示了使用不同的 COUNT 设置遍历一个包含 500 万个键的数据集所需的执行时间。
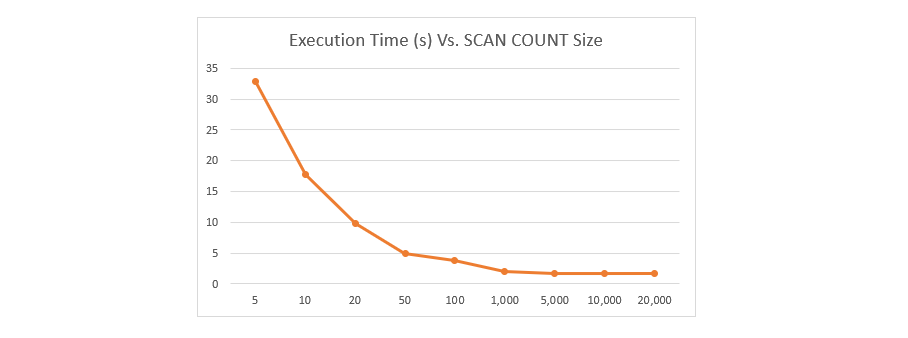
可以看出,对于非常小的 COUNT 值,遍历所有键所需的时间会显著增加。分组成较大的批量会导致 SCAN 完成的延迟更低。批量大小为 1000 或更大时,返回结果的速度要快得多。
对于 Redis,重要的是选择一个足够小的大小,以最小化命令在生产过程中的阻塞行为。
使用 SCAN 时的 Redis 性能下降#
对于 Redis,官方一直警告不要在生产环境中使用 KEYS 命令,因为它在执行查询时会阻塞数据库。SCAN 的创建就是为了分批迭代键空间以最小化影响。
然而问题依然存在,SCAN 会如何影响生产负载?如果我的 COUNT 值足够小,我可以一次运行大量的 SCAN 查询吗?
下图显示了在大型数据集上运行 SCAN 的效果,COUNT 大小分别为 100、1000 和 10,000。它展示了运行这些查询对现有工作负载性能的影响。
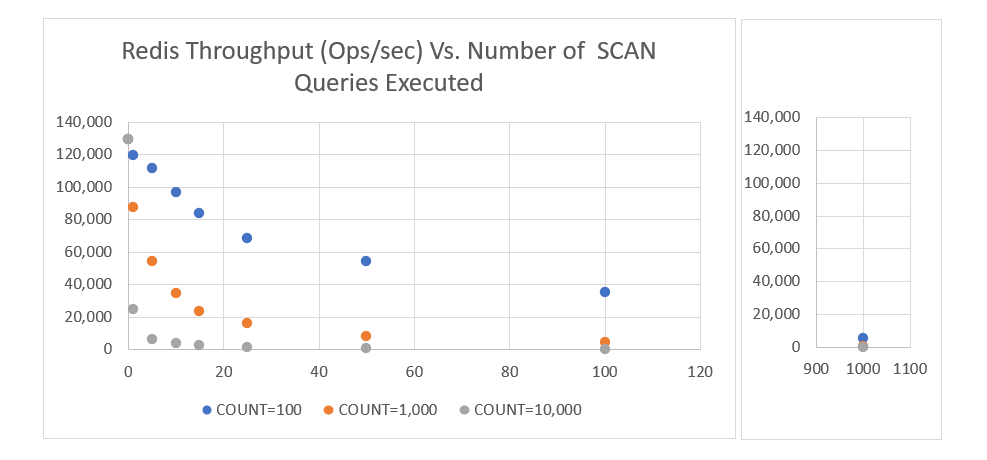
对于上述测试,我们使用 memtier 生成工作负载,并运行特定数量的 SCAN 查询来观察其对工作负载的影响。
不运行 SCAN 时的基准 ops/sec(每秒操作数)约为 128,000。很明显,随着执行的 SCAN 查询越来越多,工作负载的吞吐量会大大降低。多次迭代的累积阻塞效应很快就显现出来。这意味着减少执行的 SCAN 查询数量以防止性能大幅下降非常重要。
KeyDB 使用 MVCC 实现 SCAN#
KeyDB 在其代码库中实现了多版本并发控制 (MVCC)。这允许在不阻塞其他请求的情况下查询快照。因此,在 KeyDB 上运行 KEYS 或 SCAN 对现有的工作负载几乎没有影响。
KeyDB 也是多线程的,这使得其总体性能要高得多。
如下所示,无论 COUNT 的大小或执行的 SCAN 查询数量如何,正在运行的工作负载基本上不受影响。
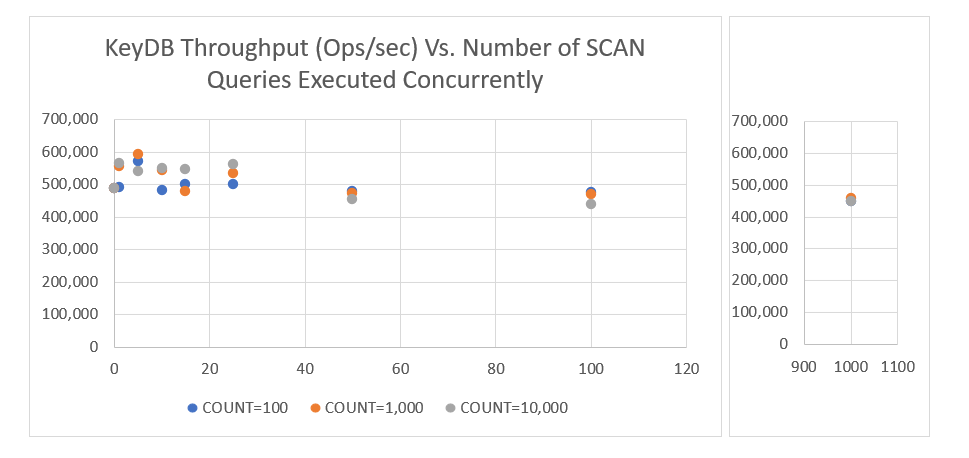
性能不会下降,KeyDB 能够并发地处理 SCAN 查询。这对于那些严重依赖 SCAN 或需要在其用例中应用 SCAN 的人来说是个好消息。使用 MVCC 带来的非阻塞行为以及我们的多线程技术为我们计划在 KeyDB 中构建的功能提供了很多机会。
Python 示例#
下面是一个如何使用 SCAN 遍历整个数据集的示例。我们使用 KeyDB python 库(Redis 库也同样适用),并定义一个函数,该函数接受一个要匹配的模式和一个 COUNT 大小。游标从 0 开始,每次迭代后更新并传回,直到再次回到起点(即遍历整个数据集)。
结论:#
希望本文能让您对如何使用 SCAN、其对性能的影响以及通过 KeyDB 的 MVCC 实现所能看到的改进有所了解。
我们对在 KeyDB 中使用 MVCC 感到非常兴奋,因为它为提升性能和提供更好的数据洞察力开辟了许多机会。在未来一年,MVCC 将使我们能够利用更多的机器核心,并在 KeyDB 的可能性上实现巨大飞跃。
了解更多:#
亲自测试#
在上述测试中,我们使用了示例 Python 代码来查询数据。数据集包含 5000 万个键,以便有足够的时间来准确测量对吞吐量的影响。在测试中,查询会并行请求多达 1000 次。整个数据集会使用不同的 COUNT 值进行迭代。
在执行查询的同时,我们使用 Memtier 及其默认设置生成了一个基准工作负载:`$ memtier_benchmark -p 6379`。记录的数据用于提供上述图表。所有测试都在同一台机器(m5.8xlarge)上进行,memtier 和 KeyDB/Redis 运行在同一台机器上。如果将 Memtier 移至其自己的机器,可以从 KeyDB 获得更高的吞吐量,但就本次测试的目的而言,该设置足以证明这个概念。
如果你想产生类似的负载,可以让你 memtier 运行 SCAN 命令,但它不会迭代整个键空间,只会为单次迭代生成请求。然而,所看到的效果是相似的。你的数据库不需要非常大就能观察到以下行为。
上述命令对 Redis 的标准 memtier 工作负载产生了以下影响
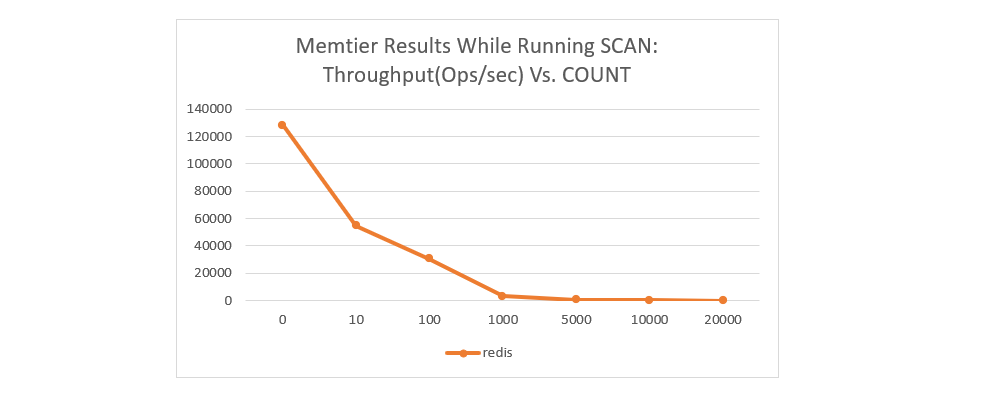
如果为此使用 memtier,你可以限制客户端数量“--clients=x”以减少生成的 SCAN 查询数量。