单个 Redis 实例能有多快?
Redis 被认为是最快的数据库之一。但如果移除一些限制,一个独立的实例能变得多快?我们常听说,在性能限制方面,Redis 更有可能达到网络或内存瓶颈,而不是 CPU 瓶颈。根据您的设置,这三者中的任何一个都可能成为瓶颈。
在本文中,我们将讨论我们如何制作了一个能让 Redis 性能几乎翻倍的模块!
回到是 CPU 瓶颈还是网络瓶颈的问题,根据我们的经验,通常两者兼而有之。EQ Alpha 推出了 KeyDB,这是一个多线程、开源的 Redis 分支,证明了多线程可以带来巨大的性能提升。然而,我们一直对另一个主要瓶颈感到困扰。性能常常被自旋锁(spinlock)和对内核的系统调用(syscall)所拖累。随着网卡(NIC)的巨大发展,Linux 在处理数据包方面成为了一个瓶颈。由于内核数据包复制、中断和系统调用,通过内核处理的数据受到限制,这发生在“内核空间”(kernel space)中。另一方面,我们在所谓的“用户空间”(user space)中运行我们的应用程序。于是问题就来了,难道没有办法绕过内核吗?是的,有。英特尔开发了其数据平面开发套件(DPDK),它提供驱动程序和库来加速数据包处理工作负载。绕过内核的想法允许数据流在用户空间中处理,而 Linux 则处理控制流。
这个想法被付诸实践,并用 EQ Alpha 刚刚发布的模块进行了测试。该模块允许 Redis 在用户空间与网卡交互,绕过内核。这使得一个普通的 Redis 独立实例的性能从 164,000 ops/sec 提高到超过 300,000 ops/sec,在一个 Redis 5.0 实例上延迟降低了约 1.8 倍。下面的图表显示了每秒操作数(Operations per Second)与数据大小(Data Size)的关系。测试使用了最新版本的 Redis(5.0),并添加了加速器模块。
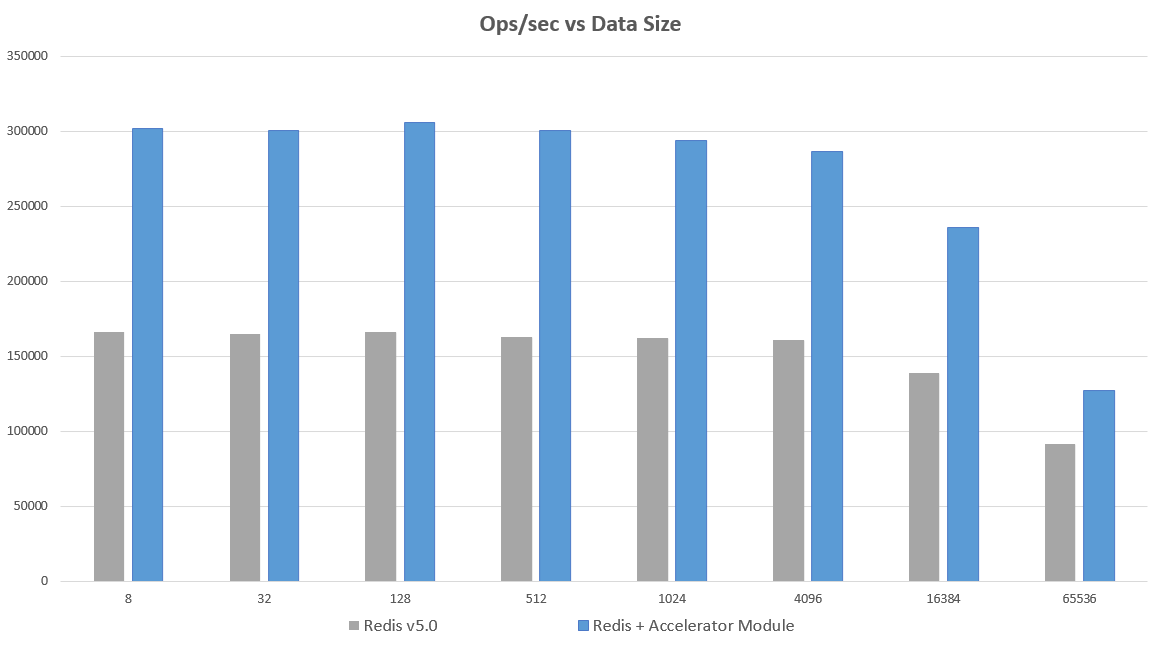
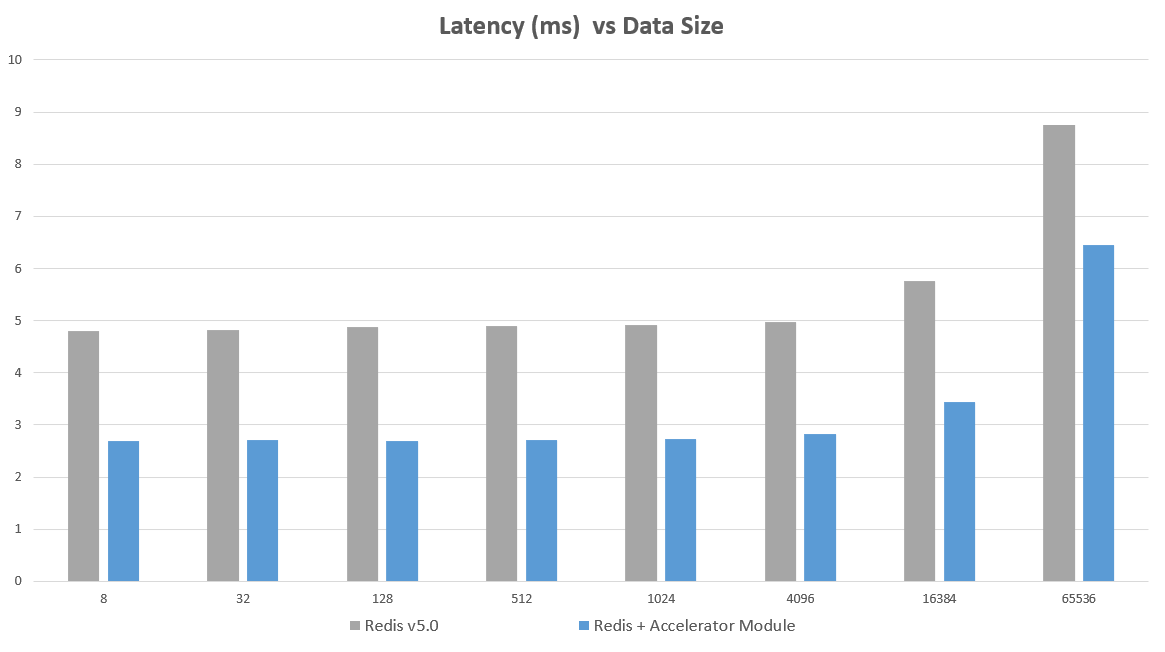
基准测试是使用 memtier-benchmark 进行的。Memtier 运行在一台 m5.4xlarge 机器上,Redis 运行在一台 m5.2xlarge 机器上。Memtier 使用 12 个线程和 100 个客户端运行,并经过测试以确保这个基准测试工具本身不是瓶颈。测试在相同的机器上进行,每种情况下都执行了相同的测试。这些结果没有使用流水线(Pipelining)。如果使用流水线,QPS(每秒查询数)会超过 200 万,不同方法之间没有显著差异。memtier_benchmark --clients=100 --threads=12 --requests=20000 -s <ipaddress> -a <password> --hide-histogram
在单机实例上(即不在同一台服务器上运行节点集群)可以看到最大的性能提升——尽管在这种情况下仍然可以看到一些提升。在同一台服务器上运行主/从(master/replica)或作为机器集群的一部分,也会有很大的收益。如果服务器受限于 CPU,性能提升可能不会那么高。建议使用拥有 4 核或更多核的机器。
这些是在用户空间内操作带来的可观收益。使用此模块可以让您的 Redis 实例在这种环境下运行,而无需修改基础代码。Redis 将通过 Unix 套接字(Unix sockets)运行,这在使用 dpdk 时能带来更快的性能。利用环境抽象层(EAL)以及其他堆栈组件,该模块能够轮询和解释数据,而没有中断处理的开销。它能够在自己的框架内运行,并允许您继续使用您的生产版本的 Redis,或任何其他版本的 Redis(包括不稳定版和新版本)。
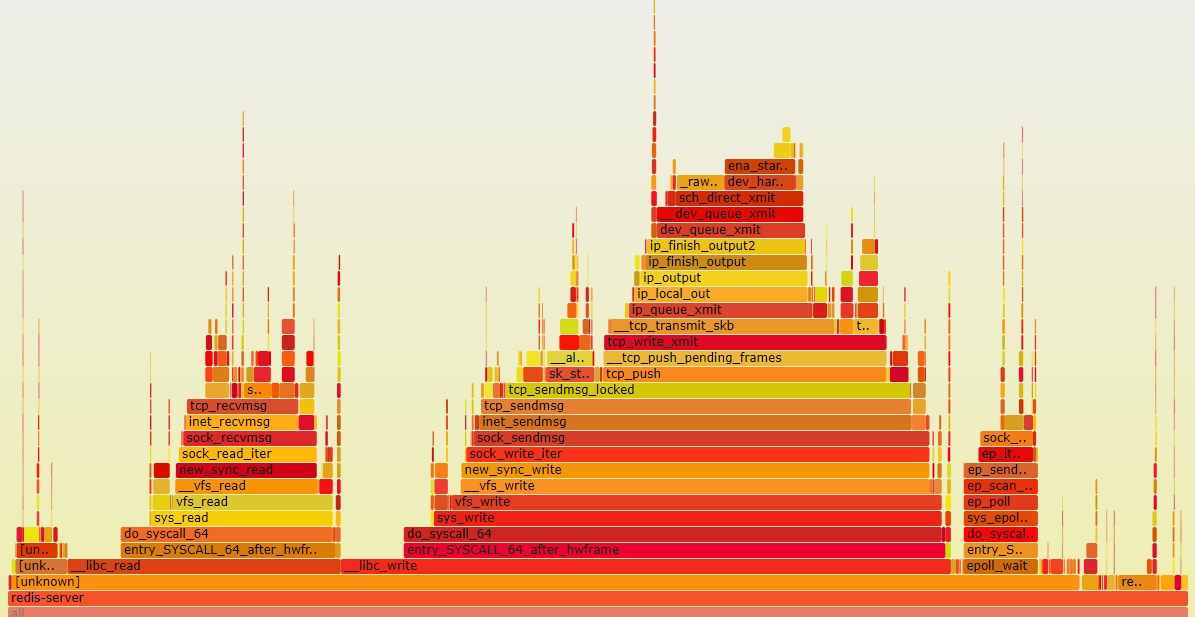
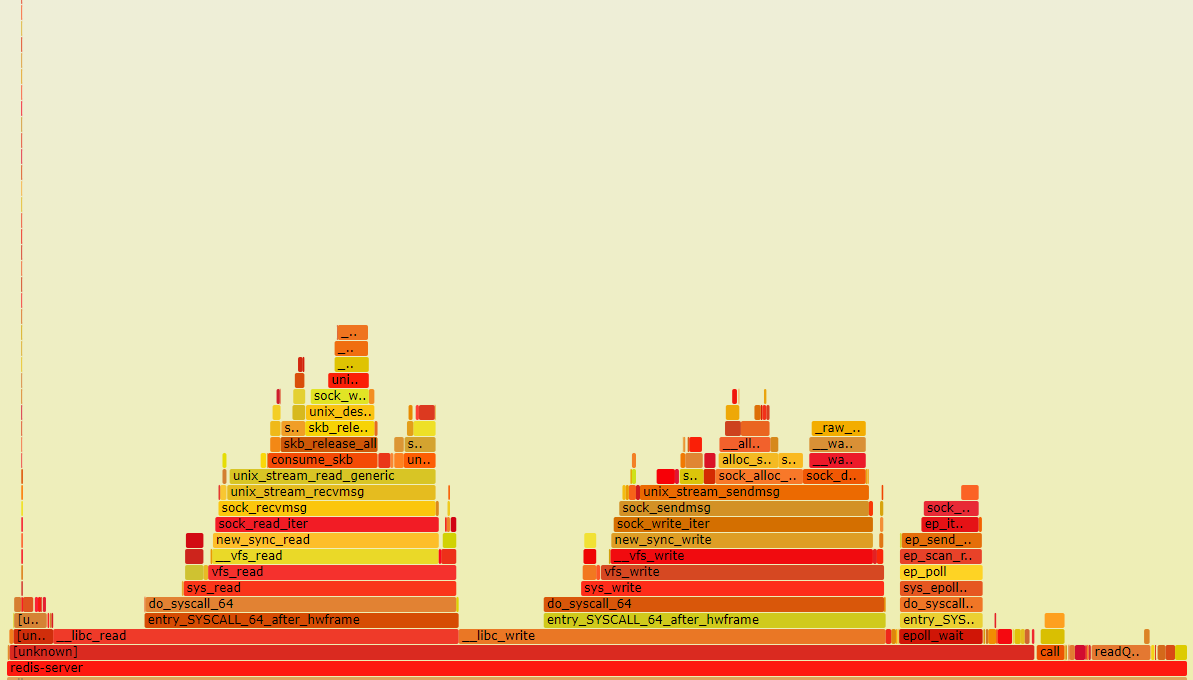
这个概念很有趣,它激发了人们对内部工作原理的好奇心。那么,一个没有这些限制的 Redis 实例运行时是什么样子的呢?下面是两张 火焰图(Flamegraphs),可以帮助可视化分析软件的性能。它们分别是在运行带模块的 Redis 和不带模块的 Redis 时生成的。
下面是在对未修改的 Redis 进行常规基准测试时生成的火焰图。
下面是在后台运行加速器模块进行基准测试时生成的火焰图。
希望本文能帮助展示您的实例可以释放的潜力。EQ Alpha 在这个模块和 KeyDB 项目上的目标之一是推动开发能够支持更大、更强大实例的选项,通过处理更多负载来最小化分片和集群的需求。这个模块以独立模块的形式存在是有益的,因为它很可能在未来的 Redis 基础代码发展和新版本中,继续提供性能提升。
如需俄语翻译,请点击此处。