在基于 Arm 的亚马逊 EC2 A1 实例上运行 KeyDB 以获得最佳性价比
我们与许多希望优化 AWS 成本的用户进行了交流。虽然大多数用户已经尝试过许多可用的基于 x86 的实例类型,但我们惊讶地发现,很少有人尝试过基于 Arm 的亚马逊 EC2 A1 实例。这些基于 Arm 的实例为多线程缓存服务器工作负载带来了独特的性能优势。要理解为什么缓存数据库,特别是 KeyDB,特别适合 Arm,我们首先需要对硬件有一些了解。
自 21 世纪初以来,CPU 性能一直在指数级增长,而内存延迟却停滞不前。1998 年购买的 DDR1 模块延迟为 15 纳秒,而今天购买的现代 DDR4 模块最好也只有 13.5 纳秒——20 年来仅提升了 10%。这对软件开发人员的启示是明确的——尽可能多地将数据保留在缓存中,并确保 CPU 能够积极地进行预取。
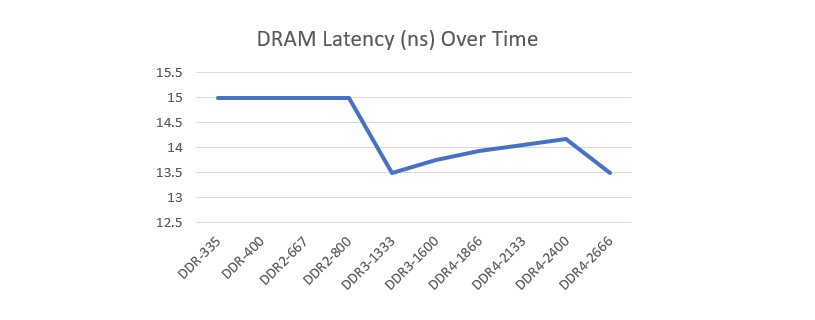
这给像 KeyDB 这样的缓存数据库带来了问题。我们数 GB 的数据集太大,无法放入缓存中,并且数据访问依赖于外部请求,这些请求无法轻易预取。结果,我们现代的超高速处理器大部分时间都在空闲等待 DRAM。在这种环境下,单线程性能受到 DRAM 延迟的限制,而核心总数成为决定整体性能的主导因素。
这正是 Arm 和亚马逊 EC2 A1 实例特别擅长的那种工作负载。每个核心的成本降低高达 45%,确保您为实际能用到的性能付费。如下图所示,实证测试也证实了这一点,在真实世界测试中显示可节省高达 30% 的成本。
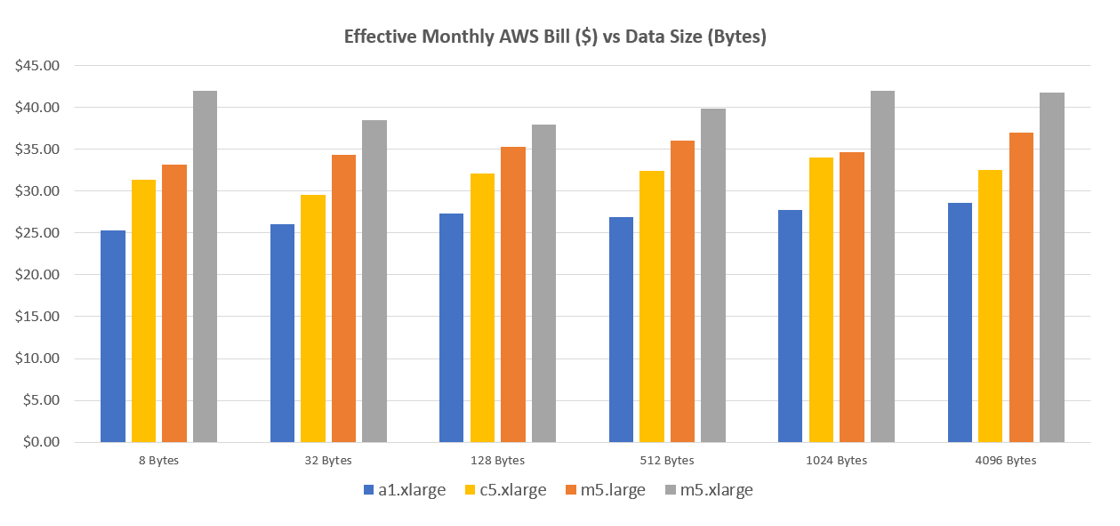
上图显示了在不同 AWS EC2 实例类型上,为实现 250,000 次操作/秒的性能目标,每月有效运行成本与所获取数据大小的关系。我们可以看到,基于 Arm 的 EC2 A1 实例始终保持成本优势。每月成本是使用预留实例定价计算的,计算公式为:[(250,000 次操作/秒) / (实例的基准测试操作/秒)] x (EC2 每小时成本) x (24 小时) x (30 天)。这将成本比较规范化,以评估单位吞吐量的成本。关于性能结果,a1.xlarge (4核, 8GB) 的操作/秒比 m5.large (2核, 8GB) 高约 30%,比 m5.xlarge (4核, 16GB) 和 c5.xlarge (4核, 8GB) 低约 30%,但从每美元提供的服务量来看,A1 实例开始显现出明显的优势。
在这个基准测试中,很明显,虽然 x86 核心的单个性能可能更快,但对于基于缓存的工作负载来说,核心总数才是最重要的——在这种情况下,Arm 变得经济得多。
由于这种固有的成本优势,我们花了很多时间来为 Arm 优化 KeyDB,我们的多线程架构使得 KeyDB 能够充分利用这类硬件。如果您希望降低缓存层的成本,KeyDB 与亚马逊 EC2 A1 实例的组合是一个强有力的选择。
这里有一些链接,可以了解更多关于 KeyDB 或 亚马逊 EC2 A1 实例 的信息。
要查看 Github 上的 KeyDB 开源项目,请点击这里
1. https://www.crucial.com/usa/en/memory-performance-speed-latency