一个比 Redis 快 5 倍的 Redis 多线程分支
如果我告诉你,有一个 Redis 的分支版本,其运行速度可以快 5 倍,延迟降低近 5 倍,你会怎么想?如果你不再需要哨兵节点,并且你的副本可以同时接受读写操作呢?这有可能将你的分片数量减少 10 倍。
本文介绍的是 KeyDB,一个开源的、多线程的 Redis 分支。我们将回顾最新的基准测试数据,并讨论一个更强大的 KeyDB 单实例如何减少集群规模并简化你的技术栈。我们还将探讨其多线程架构,并演示如何复现这些测试数据。
为何选择 KeyDB?为何考虑一个分支?#
由于能够不受限制地发展代码库,KeyDB 在短时间内取得了巨大进步,并正走在一条将在未来几个月颠覆数据库领域的道路上。
关于最初为什么要创建 Redis 分支,KeyDB 对于代码库应如何发展有着不同的理念。我们认为,易用性、高性能和“开箱即用”的方式是创造良好用户体验的最佳途径。虽然我们非常尊敬 Redis 的维护者,但我们认为 Redis 的方法过于注重代码库的简洁性,却牺牲了用户的便利性。这导致需要外部组件和变通方案来解决常见问题。
由于这种理念上的差异,适合 KeyDB 的功能可能不适合 Redis。创建一个分支使我们能够探索这条新的发展路径,并实现那些可能永远不会成为 Redis 一部分的功能。KeyDB 与上游 Redis 的变更保持同步,并在适用时向上游提交错误修复和更改。我们希望这两个项目能够继续共同成长,并相互学习。
最新基准测试数据#
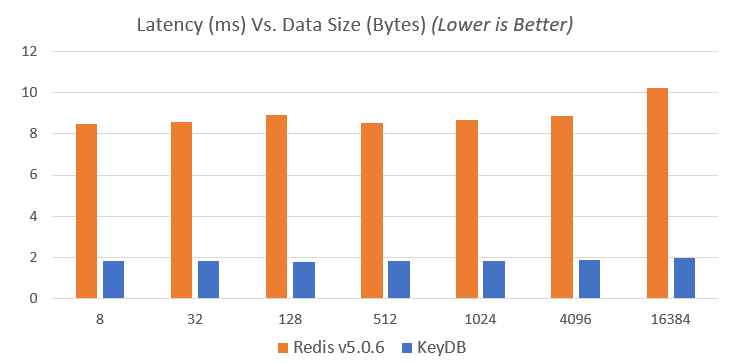
KeyDB 于今年三月发布,尽管已经取得了性能上的提升,我们仍期望能变得更快。我们最新的基准测试数据显示,单个 KeyDB 实例的 ops/sec(每秒操作数)比单个 Redis (v5) 实例高出 5 倍以上(图表范围在 5.13-5.49 倍之间),延迟则降低近 5 倍(图表范围在 4.6-5.1 倍之间)。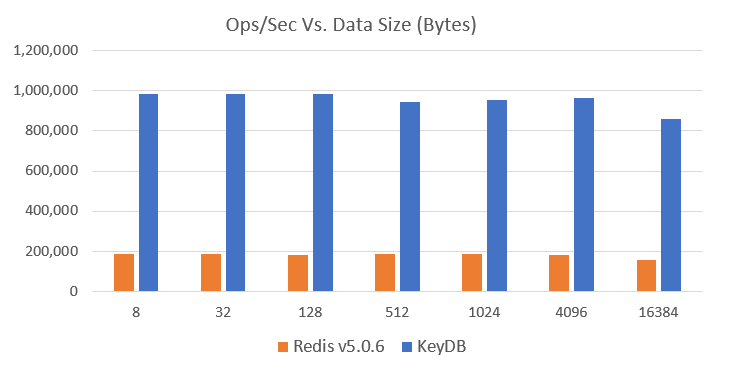
多线程的好处#
能够增强单个 KeyDB 实例/节点的能力,减少了分片的需要,并能极大地简化你配置中的活动部件数量。你可能会问,在集群中运行多个 Redis 节点是否会比在单个节点上进行多线程获得更高的每核心吞吐量?你可以像对 Redis 一样对 KeyDB 进行分片,并且随着数据库的不断增长,这样做是合理的。但如果你有办法在不购买第二辆车的情况下增加马力,何乐而不为呢?能够扩展节点规模,同时还能进行分片,为用户增加了新的能力和选择。这是 Redis 和 KeyDB 之间众多理念差异之一。这不仅是社区中常见的讨论点,在某些圈子里甚至是争议点。
那么,对于“使用更多线程运行 KeyDB 是什么样子”这个问题。我们运行了一些基础测试,以便你有一个概念。下面是一个基准测试图表,比较了 ops/sec 与所用线程数的关系。
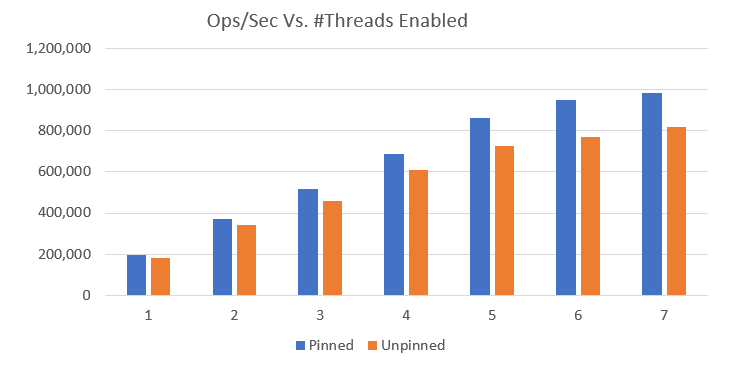
你可以看到,随着为实例分配更多资源,性能得到了显著提升。还有一个选项可以将线程绑定到 CPU 以进一步提高性能,但最佳选项可能取决于你的具体配置。默认情况下,此选项是禁用的。
即使只给 KeyDB 分配一个线程,它平均仍比单线程的 Redis 实例有大约 5% 的性能优势。所以,即便增加了新功能和架构变更,性能也并未受到影响。
多线程架构#
KeyDB 的工作原理是在多个线程上运行常规的 Redis 事件循环。网络 IO 和查询解析是并发完成的。每个连接在 accept() 时被分配一个线程。对核心哈希表的访问由自旋锁保护。由于哈希表访问速度极快,这个锁的竞争很低。事务在执行 EXEC 命令期间会持有该锁。模块与 GIL(全局解释器锁)协同工作,只有当所有服务器线程都暂停时才会获取 GIL。这维持了模块所期望的原子性保证。
与大多数数据库不同,核心数据结构是系统中最快的部分。大部分查询时间都花在解析 REPL 协议和与网络之间的数据复制上。
未来的工作包括允许在连接后将连接重新平衡到不同的线程,以及允许多个读取者并发访问哈希表。
进一步优化你的配置#
KeyDB 相信那些能简化用户体验的功能。我们的主动复制(Active Replica)功能已被广泛采用,并在我们最新的稳定版本 5 中用于生产环境。该功能使你能够拥有两个互为复制的主节点,两者都接受读写操作。最棒的是,没有哨兵节点来控制故障转移。你获得了高可用性,并最大化了资源利用。如果你还没有将读取操作负载均衡到副本节点,使用这个选项可以使你的吞吐量翻倍。这意味着,从简单的 Redis 主从复制配置迁移到 KeyDB 的多线程主动复制配置,可以将你的分片需求减少多达 10 倍。请参阅这篇文章《Redis 复制与 KeyDB 主动复制:优化系统资源》,以深入了解主动复制这个主题。
了解 KeyDB#
要查看 Github 上的 KeyDB 开源项目,请点击这里
基准测试 – 如何自行复现这些测试:#
进行基准测试时,最重要的事情是确保你的基准测试工具本身不是瓶颈。我们需要使用一台分配了 32 核的亚马逊 m5.8xlarge 实例,才能为我们的单实例测试产生足够的负载量。任何配置更低的实例都会导致基准测试工具成为这些测试的瓶颈。对于测试实例,我们使用了 RedisLabs 的 Memtier 。在我们的测试中,运行 Redis 和 KeyDB 实例的机器是一台亚马逊 m5.4xlarge。
对于比较 Redis 和 KeyDB 的第一个图表,使用了以下命令Memtier: memtier_benchmark -s [测试实例的IP] -p 6379 –hide-histogram --authenticate [你的密码] --threads 32 –data-size [测试数据大小,范围 8-16384]
KeyDB: keydb-server --port 6379 --requirepass [你的密码] --server-threads 7 --server-thread-affinity true
Redis: redis-server --port 6379 --requirepass [你的密码]
Memtier: memtier_benchmark -s [测试实例的IP] -p 6379 --hide-histogram --authenticate [你的密码] --threads 32 --data-size 32
KeyDB (绑定线程): keydb-server --port 6379 --requirepass [你的密码] --server-threads [测试所用线程数] --server-thread-affinity true
KeyDB (不绑定线程): keydb-server --port 6379 --requirepass [你的密码] --server-threads [测试所用线程数]