使用 KeyDB 对 AWS Graviton2 进行基准测试——M6g 速度提升高达 65%
我们一直对 Arm 充满热情,所以当亚马逊为我们提供其新款基于 Arm 的实例的早期体验机会时,我们迫不及待地想看看它们的性能如何。我们所说的当然是由 AWS Graviton2 处理器驱动的 Amazon EC2 M6g 实例。Graviton2 的性能宣传和热议让我们急于想知道我们的高性能数据库在其上会有怎样的表现。
本文比较了 KeyDB 在几种不同的 M5 和 M6g EC2 实例上的运行情况,以深入了解其成本、性能和用例优势。结果数据相当令人兴奋,AWS Graviton2 名不虚传,希望您会喜欢!
KeyDB 是一个多线程的 Redis 超集,由于其先进的架构,能够实现比 Redis(节点对节点)高出 5 倍的性能。我们已经在 AWS 实例上做了大量的基准测试(在此处比较),结果显示使用某些实例类型比其他类型有明显优势。到目前为止,M5 实例一直是 AWS 上可用的最快的通用 Amazon EC2 实例,因此与可能更快的 M6g 进行比较,阵容非常有趣。
性能与成本#
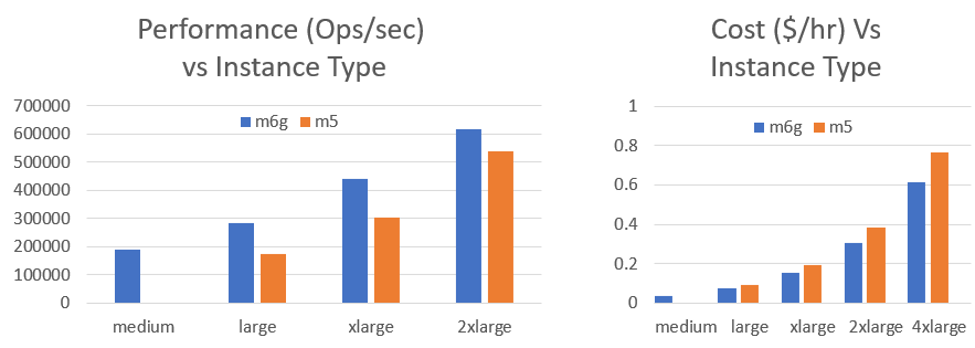
第一张图表比较了几个不同实例大小的性能,着眼于每个实例可以达到的每秒操作数(ops/sec)吞吐量。第二张图表包含每种实例类型的相关定价。您可以在此处选择美国东部(弗吉尼亚北部)来比较 M6g 的定价。
M6g 占据领先地位#
M5 实例使用英特尔至强铂金 8175 处理器,这通常能让我们在大多数其他可用实例类型上获得非常好的结果。令我们震惊的是,在较小的 M6g 实例上,使用 AWS Graviton2 处理器,KeyDB 相比现有的 M5 实例获得了如此巨大的提升。
m6g.large 比 m5.large 快 1.65 倍,而 m6g.xlarge 比 m5.xlarge 快 1.45 倍。随着核心数量的增加,两者之间的差距开始缩小。然而,我们仍在研究 m6g.2xlarge 和 m6g.4xlarge 的性能,因为我们相信可以将性能水平提升到同样的倍数。在这次测试中,我们没有针对 M6g 进行任何特定的调优,所以我们对未来的结果持乐观态度。
同样令人高兴的是,M6g 系列中提供了 m6g.medium 实例(M5 系列没有),这又增加了一个功能强大且成本更低的选择。从上面的图表中可以明显看出,M6g 实例不仅比 M5 提供了主要的性能提升,而且还便宜了 20%!
这对用户意味着什么#
KeyDB 是一个非常快的内存数据库。因此,我们的用户非常重视内存和性能。KeyDB 一直是我们 ARM 用户和用例的倡导者。我们很高兴能够支持 M6g,它正显示出是其 x86 对手的强大竞争者。对于那些将所有数据都保存在内存中的用户来说,更低的内存成本和额外的计算能力为 M6g 提供了强有力的理由。
对于试图降低成本的用户来说,按比例扩展数据库大小与计算资源可能是一个艰难的平衡。有很多用户在选择 EC2 实例时首先会受到内存的限制。在优化资源和降低成本时,通常会选择 KeyDB FLASH 功能,它在 RAM 之外增加了一个快速的 FLASH 层。M6g 系列通过功能强大的较小实例来补充这些用例,从而实现了一些最经济实惠和资源优化的数据库解决方案。
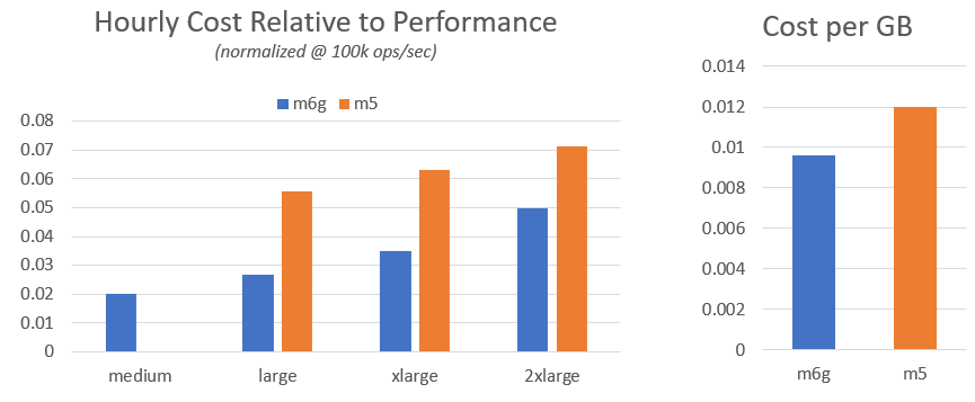
下面的第一张图表展示了成本与性能的关系。这张图表代表了“性价比”,其中 m6g.medium 为您的每一分钱提供了最多的计算能力,而每个后续的更大尺寸在计算能力方面也提供了显著的节省。第二张图表着眼于内存(RAM),在 GB 对 GB 的尺度上,M6g 实例也为每花费一美元提供了更多的内存。
在下面的两种情况下,数值越低越好,表示每单位资源的成本更低。
结论#
从以上结果来看,M6g 实例在每 GB 尺度上便宜 20%。这可以为用户带来全面的成本节约,特别是那些根据可用内存选择机器大小的用户。
在工作成本方面,当考察计算成本/性能时,一些 M6g 实例可以便宜超过 2 倍。m6g.medium 提供了最佳的性价比,m6g.large 和 m6g.xlarge 也具有显著优势。
从纯性能来看,m6g.large 比 m5.large 快 1.65 倍,比较 ‘xlarge’ 实例时则快 1.45 倍。
很明显,这些处理器不仅能提供性能提升,还能带来显著的成本节约!看来 AWS Graviton2 在经受考验时确实名副其实。凭借其有竞争力的定价,Graviton2 似乎将在云业务中留下自己的印记。
了解更多#
复现基准测试#
我们鼓励用户试用 M6g,看看相对于您的用例能看到什么样的改进和/或节省。本节回顾了复现本博客中所示结果的基准测试步骤。我们还看了一些技巧,以帮助减轻瓶颈和测试差异。避免瓶颈
- 我们使用 RedisLabs 的 Memtier 进行基准测试。由于 KeyDB 的多线程和性能提升,我们通常需要一个比运行 KeyDB 的机器大得多的基准测试机。我们发现需要一个 32 核的 m5.8xlarge 才能用 memtier 产生足够的吞吐量。这支持高达 16 核 KeyDB 实例(medium 到 4xlarge)的吞吐量。
- 使用 Memtier 时,运行 32 个线程。
- 在同一网络上运行测试。如果比较实例,请确保您的实例在同一个可用区(AZ)。
- 使用私有 IP 地址运行。如果您使用 AWS 公有 IP,可能会有更多的差异。
- 注意不要通过代理或 VPC 运行。当使用这些方法、防火墙和附加层时,很难确定瓶颈可能在哪里。最好在简单的环境中进行基准测试,然后再添加各个层,以确保您已优化。
- 请记住,延迟数字是相互关联的。Memtier 测试推动的是最大吞吐量。像 YCSB 这样的工具非常适合在不同负载下(而不仅仅是最大吞吐量)精确测量延迟数字。
- 在比较不同的机器实例时,请确保它们在同一个可用区,并且测试时间尽可能接近。一天中的网络吞吐量会变化,因此将测试安排得尽可能接近,可以提供最具代表性的相对比较。
- KeyDB 是多线程的。运行时请确保指定多个线程。
设置 KeyDB#
您可以通过 github、docker、PPA(deb 包)或 RPM 获取 KeyDB。安装后,使用以下配置参数启动它
尝试在本博客中所示的不同实例类型上运行
设置 Memtier 并进行基准测试#
从 github 安装 memtier。安装后,您可以使用以下命令行运行测试
memtier 和 KeyDB 都假定使用端口 6379,但也可以指定。您需要设置您的 aws 安全组规则以允许通过此端口的访问。如果在空数据库上运行,上述命令将返回所有未命中。为了加载数据库,您可以使用此命令
在运行正常基准测试时,这将返回具有代表性的数字。如果您想在基准测试中获得 100% 的命中率,您将需要先通过以下命令用所有写操作来加载它
当您运行一个正常的基准测试时,它现在将返回 100% 的命中率
结束语#
在基准测试中看到的比率,无论命中/未命中/读写设置如何,都大致保持不变。显示的数字是平均值。这是在对 M5 和 M6g 进行相对比较。运行几次连续的测试以确保可重复性。如果存在差异,增加 --requests=20000 或更高(默认为 10000)可能会有所帮助。